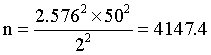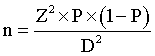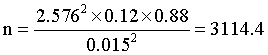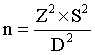
Sample size for a confidence interval (January 26, 2000)
This page is moving to a new website.
Dear Professor Mean, We have a large dataset with about 400 million records. We need to randomly select a subsample from it. However we need help in determining the sample size. What sample size do we need for the confidence interval calculations? -- Frantic Frank
Dear Frantic,
400 million records? I bet your fingers are tired from all that typing.
There are several approaches for determining the sample size. The simplest is to estimate what sample size will provide confidence intervals that are narrow enough for your needs. You might say, "I want the interval to be as narrow as possible," but that's not really true. There is a certain level of precision, which if you exceed it, becomes clinically irrelevant. You don't need to know the average cholesterol levels, for example, with a precision of two or three decimal places. The smallest difference that is still important to your clinicians will determine your sample size.
By the way, don't expect me (or any other statistician) to tell you how much of a difference is considered clinically relevant. I have enough trouble understanding the difference between good and bad cholesterol. The narrowness of the intervals should be determined by medical expertise.
What else do I need to specify?
Beyond specifying how narrow you really need the intervals to be, you need to have at least a rough idea about how variable your outcome measure is. You could randomly select a few hundred records from your data base and estimate a standard deviation. You only need a rough estimate of the standard deviation, so anything more than a few hundred records is overkill.
If you can't pull out a few hundred records in advance, you would try to find information, perhaps in publications of similar research studies, about the variability of your outcome measure. You're not going to find published research that is identical to what you are doing, but anything close should be fine.
When you find that publication, look for a standard deviation. If no standard deviation is given, sometimes you can estimate it using other measures of variability such as the standard error, the range, confidence limits, or even information about the percentiles of the data.
Example
If you let D represent the minimum detectable difference and S represent the standard deviation, and Z represent the 1-alpha/2 percentile of a standard normal distribution, then the appropriate sample size would be
Suppose you wanted a confidence interval for average cholesterol level to have a precision of plus or minus 2 units. And let's suppose that the standard deviation for cholesterol in a population similar to yours is 50 units. If we wanted a 99% confidence interval (let's be extravagant, since we have 400 million data points to choose from!), then Z would be 2.576. Applying the formula, we get
which we round up to 4,148.
What if I am estimating a proportion?
If you're estimating a proportion rather than a mean, the process is similar except that instead of a standard deviation, you need a rough estimate of what you think the proportion might be. It doesn't need to be all that accurate an estimate. A ballpark figure is fine.
If P is your guess at what the proportion should be, then the sample size needed would be
Suppose we wanted to estimate the proportion of adverse drug events to plus or minus 1.5% and we know that the proportion will be around 12%. Again, let's use a 99% confidence level. Then the sample size would be
which we round up to 3,115.
At this point, you might protest and say, but I don't know the proportion! That's probably true; if you already knew the proportion, you wouldn't need to do the research. But I suspect that you have a rough idea of what the proportion might be, either from your intuition or from previously published research in the area.
If you really have no idea what the proportion might be, then use p=0.5. That gives you a worst case scenario, meaning the largest sample size. If your proportion is much bigger or much smaller than 0.5, then your interval will be narrower than you might expect, but hardly anyone ever complains if their interval is narrower than planned.
Summary
Frantic Frank needs to randomly select some records from a database that has 400 million of them. He wants to know how many records he should select. Professor Mean suggests that confidence intervals would be a good way to summarize information from this type of random sample. He suggests that you select enough records so your confidence intervals are reasonably narrow.
Further reading