Three things you need for a power calculation (created 2001-11-08, revised 2011-04-26).
This page is moving to a new website.
Dear Professor Mean, I want to do research. Is forty subjects enough, or
do I need more? -- Eager Edward
Dear Eager,
That reminds me of a cute joke. How many
research subjects does it take to screw in a light bulb? At least 300 if you
want the bulb to have adequate power.
Sorry, I was digressing. Is forty subjects an
adequate sample size? That depends on a lot of factors. The basic idea,
though, is to select a sample size which ensures that your study has adequate
power. Power is the probability that your research study will
successfully detect a difference, assuming that the treatment or
exposure you are examining actually can cause an important difference. If you
don't care whether your experiment is successful or not, then you can use
just about any sample size.
Short answer
Power is to a research design like sensitivity
is to a diagnostic test. A diagnostic test with good sensitivity is normally
able to detect a disease when the disease is present. A research study with
good power is normally able to detect a change when your treatment is indeed
effective.
The actual calculation of power requires three
pieces of information:
- your research hypothesis,
- the variability of your
outcome measure, and
- your estimate of the clinically
relevant difference.
Calculating power is sometimes difficult and
it may require you to go to the time and expense of running a pilot study.
But you should NEVER start a research project without knowing what
your power is. That would be like using a diagnostic test with
unknown sensitivity.
Research hypothesis
A research hypothesis will
provide specific information that will determine what type of analysis is
needed. A common structure for a research hypothesis
is specification of the subject group you are
testing, the treatment or exposure that this group will
receive, the outcome measure, and the comparison or
control group.
Some exploratory studies may not have a
research hypothesis, of course, and for those studies you determine an
appropriate sample size in a different way (for example, by insuring that the
estimates from this exploratory study have adequate precision).
Variability of your outcome measure
You also need to have an estimate of the
variability of your outcome measure. I'm assuming here that
your outcome measure is continuous variable like birth weight or cholesterol
level. If you are using a categorical outcome measure like mortality or
cancer remission, then you need some estimate of the rate of mortality or
remission in your control group.
Your literature review (you did do a
literature review before you started this research, I hope), will usually
provide you with an estimate of variability. Select a study that is
reasonably similar to what you plan to do, and find out what that
study reported for the standard deviation for your outcome measure.
Although I prefer a standard deviation,
other estimates of variability are also acceptable. If the
paper reports a variance, a standard error, a confidence interval, or a
coefficient of variation, then there are simple formulas for converting these
into standard deviations. If the study priveds a range, then you can
divide the range by four to get a good approximation for the standard
deviation.
Many of the people I see have a
difficult time providing any estimate of variability. This area
hasn't been studied before, so no one knows what the variability will be. But
don't give up too easily.
First keep in mind that you only need
a crude estimate of variability. Power calculations are capable of
determining if you are "in the right ball park." They are good at specifying
your sample size down to an order of magnitude perhaps but not much more than
that. In other words, might tell you whether you need hundreds of subjects
dozens of subjects instead of hundreds of subjects, or possibly if you need
thousands of subjects.
Second, although most research is innovative and therefore unique, this
innovation is often in the treatment and not in the outcome measure. So
look for studies that used the same outcome measure, even if
the treatment is quite different than yours.
Third, try to characterize variability in your control group
and we can try to extrapolate what the variability will be in the treatment
group. A retrospective chart review, for example, will provide a rough
estimate of variability of your outcome measure under the current standard of
care.
Third, you may have to use a clearly flawed estimate, but a flawed
estimate of variability may still be better than no estimate at all.
An estimate of variability in adults, for example, may not be an ideal
estimate for a pediatric study, but at least it tells you if your study will
have adequate power assuming that the variation in a pediatric population is
comparable to variation in an adult population. That's still better than
having no idea whether your study has adequate power.
If you've tried and you still can't come up with an estimate of
variability, then don't despair. A pilot study can provide you with
an estimate of variability when all else fails. Usually 20 to 30
subjects produce a reasonably stable estimate of variability. A pilot study
is also helpful for finding out how quickly you can recruit subjects.
Furthermore, a pilot study will also identify any weaknesses in the logistics
of your research. Finally, if the protocol remains substantially unchanged
after the pilot study, you can usually include those pilot subjects in the
final analysis.
Clinically relevant difference
Wow, that was exhausting! You're not done, though, until you can tell me
what a clinically relevant difference would be for your
outcome measure. This is a difference that is large enough to be
considered important by a practicing clinician.
For just about every type of study, some differences are so small
as to be clinically meaningless. From a theoretical viewpoint,
perhaps, changes of any size might be interesting. But theory and practice
are very different. If a six month diet program produces an average weight
loss of three pounds, a fever medicine reduces average temperature by half a
degree Fahrenheit, or a smoking cessation program helps an additional two
percent to quit, who cares what the theoretical implicaitons might be.
It's not easy but this is something that you have to do for yourself.
The clinically relevant difference is determined by medical experts
and not by statisticians. Hey, I'm still trying to understand the
difference between good and bad cholesterol; I wouldn't even be able to start
thinking about how much of a change in cholesterol is considered clinically
relevant. You might start by asking yourself "How much of an
improvement would I have to see before I would adopt a new treatment?"
Also, try talking with some of your colleagues. And
look at the size of improvements for other successful treatments.
Still, there are some general guidelines that might help. Try looking at
the resolution of your measuring device, thinking in terms
of relative changes, or specifying changes with
respect to your standard deviation.
Average changes that are smaller than the resolution of your
measuring instrument are probably not clinically relevant. For
example, Apgar scores can take on any whole number between 0 and 10.
Gestational age can only be measured accurately to within a week In these
contexts, it is clear that average changes should probably be greater than
one unit in order to achieve relevance.
Still this is not a perfect rule. We can measure weights
to within a gram, but changes in birth weight would have to be in the
hundreds of grams or more to be meaningful. And while no family can have a
fractional number of children, decreasing the average family size by 0.2
children can have a profound effect on society.
It also may help to think in terms of relative changes. If
you can change something by 25 percent or 50 percent, that is considered
relevant in most contexts. It becomes harder to argue clinical relevance for
changes of less than 10 percent. Again, this is not a perfect rule.
Finally, you might find it easier to specify changes with respect
to your standard deviation. This type of change is called an
effect size. A common classification is that 0.2 standard
deviations is considered a small effect size,
0.5 standard deviations is considered a medium
effect size, and 0.8 standard deviations is considered a
large effect size.
An effect size of 0.2 is small enough that there is
no obvious visible separation between the two groups. The
difference in average heights between 15 and 16 year old girls is 0.2
standard deviations. An effect size of 0.8 is clearly visible.
The difference in average heights between 14 and 18 year old girls is 0.8
standard deviations.
It may be unrealistic to look for changes much
smaller than 0.2 standard deviations because the
sample sizes become prohibitively large. It may also be unrealistc to expect
to see changes much larger than 0.8 standard deviations
since this size change does not seem to occur too often in the published
literature.
Like the other two rules, this rule is also not perfect.
In some animal experiments, for example, the similarity in the gene pool can
often reduce variation to such an extent that changes of more than a full
standard deviation are quite realistic. If you are trying to specify
a clinically relevant difference, there is no substitute for a good
understanding of the context of your research.
But I can't do it.
A lot of people tell me that they can't do this. They can't provide an
estimate of variability or they can't determine what a clinically relevant
difference is, even after I explain all of the above suggestions.
But you have to do it.
The CONSORT Guidelines require you to have an a priori justification of
sample size for publication. If you don't do this now, you won't be able
to publish the data in any journal that uses these guidelines. What's the
point of doing the research if you can't publish it?
If your research requires an ethical review (e.g., through an IRB), they
will require the same a priori justification. If the research involves
animals, the appropriate animal care and use committee will require this
justification.
The bottom line is that if you know so little about this avenue of
research that you can't even come up with a preliminary estimate of the
variability of your outcome variable, then you shouldn't be doing the
research. You need instead to:
- do a more thorough literature review,
- collect some pilot data, or
- switch to an outcome measure whose variability is known to some extent.
But do something, because your ability to perform the research and to
publish your research depends on your justification of the sample size.
Example
In a study of two different skin barriers for burn
patients, we are interested in three outcome measures: pain, healing
time, and cost. We will randomly assign half of the patients to one
skin barrier and half to the other.
For pediatric patients we usually measure pain with the Oucher, a
five point scale that has been validated for children. A review of
previous studies using the Oucher have shown that it has a standard
deviation of about 1.5 units. We would be interested in seeing
how large a sample size is needed to show a change of 1 unit, the
smallest individual change attainable on the Oucher. We want to have
a power of .80, or equivalently, the probability of a Type II error of .20.
The formulas for sample size vary from problem to problem. The sample size
needed for a comparison of two independent groups is

We use the letter "z" to represent a standard normal distribution.
Alpha represents the probability of a Type I error (usually .05).
Beta represents the probability of a Type II error (we
usually want this to somewhere between .05 and .20). Sigma represents
the standard deviation, and this formula allows for the possibility
of different standard deviations in group 1 and group 2. Don't forget that
the formula requires you to square these standard deviations. Finally,
D is the clinically relevant difference. In our example,
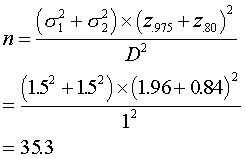
We round up. So in order to achieve 80% power for detecting a one
unit difference in the Oucher score, which has a reported standard deviation
of 1.5, we would need to sample 36 patients in each group.
Healing time is a more difficult endpoint to assess. Medical textbooks cite
that the healing time for second degree burns has a range of 4 days
(minimum 10, maximum 14). A study of healing times for a glove made
from one of the skin barriers showed a healing time range of 6
(minimum 2 and maximum 8 days).
A rule of thumb is that the standard deviation is about one fourth
to one sixth the size of the range. So we could have a
standard deviation as small as 0.67 or as large as 1.5. An average
change of one day in healing time would be considered clinically
relevant.
If we use the largest possible estimate of standard deviation, we would get
(coincidentally) the exact same sample size of 36 per group.
If we used the smallest estimate of the standard deviation, we would need
only 7 subjects per group.
For one type of skin barrier, a study of costs showed a range of
$4.00 ($5.50 to $9.50). We would like to be able to detect a
difference as small as $0.50 in costs.
Using the same rule of thumb, we get an estimate of the standard
deviation of either 0.67 or 1.0. Using the smaller estimate of
standard deviation, we would need 29 subjects per group using the
smaller estimate of standard deviation. We would need 63
subjects per group, using the larger estimate.
A sample size of 63 is untenable, so we decide that we can live
with a study that could only detect a $1.00 change in costs. For
this size difference, we would need 16 subjects per group using the
larger standard deviation.
In summary, to achieve adequate power for all three endpoints, we
would need 36 patients per group,. This is larger than we need for
the healing time endpoint. It is also larger than what we need for the cost
endpoint, unless we wanted to detect a $0.50 change in costs. To detect such
a small difference, we need a sample size of 63 subjects per group.
An earlier version of this webpage appeared on my old website at:
--> www.childrensmercy.org/stats/size/power.asp
but is no longer available there.