Quick sample size calculations (created 2001-10-11, revised 2011-04-26).
This page is moving to a new website.
Dear Professor Mean, I'm reading a research paper. I suspect that the
sample size is way too small. I don't like the findings of the study anyway, so
I'm hoping that you will help me discredit this study. Is there a quick sample
size calculation that I can use? -- Cynical Chris
Dear Cynical,
That's not a paper that I wrote, is it? I was very tired, and the dog ate
my homework, and the Year 2000 bug just struck (my computer procrastinates
worse than I do).
The simplest way to see if your sample size is too small is to look
at the confidence intervals. Look for a confidence interval so wide
that you can drive a truck through it. Look for an interval that contains
both clinically large and clinically insignificant values.
What? The paper doesn't have any confidence intervals? That's terrible.
Many journal editors require the use of confidence intervals instead of
p-values in their publications. Write a letter to the editor and complain.
A second way to assess the sample size is to do a quick power calculation.
If your research paper compares two groups (e.g., a treatment group and a
control group), then you can use the rule of 50 or the rule 16. The first
rule applies for categorical outcomes; the second applies for continuous
outcomes.
Assumptions
These rules presume that you are comparing two groups.
Some examples would be comparing a control group to a treatment group, a
standard therapy to a new therapy, or an exposed group to an unexposed group.
They also presume that you are performing
- a two-sided test,
- the alpha level is .05, and
- the power is 80%.
Finally, keep in mind that both rules are approximations, which means that
you need to consult with a statistician for an official sample size.
Still, these quick rules help you get a feel for whether you need dozens
versus hundreds versus thousands of research subjects. These quick rules are
also helpful when you are reading someone else's research and you want to get
a rough idea about what an appropriate sample size might be.
By the way, I have to give credit where credit is due. Both of these rules
came from a website with the title "STRUTS: Statistical Rules of Thumb" which
is no longer on the web. There is a book out with the same title (see further
reading) as well as a new website. Unfortunately, the details about the rule
of 50 seem to have disappeared in the update.
The rule of 50
The rule of 50 applies when your outcome measure is a discrete event such
as morbidity or mortality. The rule works well if that event is relatively
rare. If you want enough subjects to be able to detect a halving of risk from
your control group, be sure to collect enough data so that you will have at
least 50 events in your control group. Then sample the same number of
subjects in your treatment group.
For example, patients using a control medication will have a risk over five
years for a heart attack of roughly 8%. You want to try a new drug to see if
it can reduce the risk to 4%. You would need a large enough sample in each
group to ensure that at least 50 patients in the control group will have a
heart attack. It seems a bit morbid to plan for such a thing. Still, it makes
sense. If hardly anyone in either group has a heart attack, you will have a
hard time deciding whether one medication is better than another.
A control group of 625 subjects would suffice (8% of 625 is 50). With the
same number of treated subjects, you would have a total of 1,250 patients in
your study. This is just an approximation. The sample size that provides 80%
power for detecting a halving of risk is actually 553 per group, not 625.
The rule of 16
The rule of 16 applies when your outcome measure is continuous, such as
birth weight. For the continuous outcome, you need to define how much of a
difference you would consider to be clinically significant, and then compute
the ratio of this clinically significant difference to the standard deviation
of the outcome measure. This ratio is called the effect size or the
standardized effect size.Your sample size per group is 16 divided by the
square of the effect size.
For example, you are measuring the duration of breast feeding in a sample
of newborn infants. Let's presume that any intervention that can increase the
average duration of breast feeding by at least two weeks is considered
clinically significant. Furthermore, in this population, you expect the
standard deviation of breast feeding duration to be 10 weeks. The effect size
is 0.2, and the required sample size per group is 400 (=16/0.04).
Again, this is just an approximation. The sample size that provides 80% for
detecting a two week shift in breast feeding duration is actually 394, not
400.
Disclaimer: I am not a medical expert, so I cannot say
with any authority whether two weeks of additional breast feeding is
clinically significant. All my knowledge of breast feeding comes from
experiences more than forty years ago.
Example of a hypothetical research study (using the rule of 50)
An article by Schwartz et al proposes an interesting scenario for a
research study (N Engl J Med. 1998;338:1709-1714). These authors
noticed an association between prolonged QT interval and Sudden Infant Death
Syndrome. In the discussion of these findings, the authors raise the
possibility of screening all newborn infants using electrocardiography and
the placing those infants with prolonged QT intervals on a beta blocker. The
authors discuss the complexity of the cost benefit issues, which is beyond
the scope of this web page. It is interesting, however, to speculate on how
to test whether beta blockers would be effective as a therapy to prevent SIDS
in those infants with long QT intervals.
The paper provides much interesting data to help you calculate an
appropriate sample size for this study. The risk of SIDS in infants with
prolonged QT intervals is 1.5%. Suppose that a beta blocker could cut this
risk in half (to 0.75%). What sample size would you have to collect in order
to have adequate power?
The rule of 50 tells us that we would need 50 SIDS events in the placebo
arm of the trial. At a rate of 1.5% that translates into recruiting 3,333
infants with prolonged QT interval for the placebo arm. You would recruit a
similar number of infants for the beta-blocker arm of the study.
Not every infant, however, will have a prolonged QT interval. The cutoff
used in this paper for a prolonged interval represented the 97.5 percentile.
So only 2.5% of the infants screened could qualify to be in the study. In
order to recruit 6,666 infants who qualify for the study, you would have to
screen 266,640 normal infants.
Disclaimer: I am not a medical expert, so I cannot comment
intelligently on cost benefit issues, the amount of improvement that a beta
blocker might have, and other related issues. This example should only serve
as an illustration of how difficult it would be to prospectively examine a
therapy in a group of children where both the adverse event and the
qualifying condition for therapy are both rare.
Assessing the sample size in an existing publication (using the rule
of 16)
An article by Adkinson et al presents a negative finding on the use of
immunotherapy for asthma in allergic children (N Engl J Med.
1997;336:324-331). You may want to examine whether this negative finding is
due to an inadequate sample size.
One of the outcome measures is change in medication score, which has a
standard deviation of roughly 2.0. Suppose you felt that a difference of one
unit on the medication score represented a clinically significant effect.
This represents a standardized effect size of 0.5 +1.0/2.0). Using the rule
of 16, you would want 64 (=16/0.25) subjects in each group to have adequate
power.
Another outcome measure is change in symptom scores, which has a standard
deviation of roughly 0.4. If you believed that a 0.25 unit change in the
symptom score, this would represent a standardized effect size of 0.625.
Using the rule of 16, you would need 41 patients in each group.
The actual study had 60 and 61 patients, so the sample size appears
adequate (presuming that the differences of 1.0 and 0.25 are reasonable
values).
Disclaimer: I am not a medical expert, so I can only
speculate on what a clinically significant difference would be. Also, there
are some tricky issues in the paper involving compliance and the quality of
care received. My discussion of this example may oversimplify some of the
issues, but I hope you still find the example interesting and informative.
Mathematical details
The rule of 50 starts with the a standard formula for sample size.
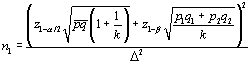
If the event in question is rare, then
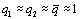
Suppose we want to detect a 50% decline from group 1 to group 2. We want
the same number of subjects in both groups, we want a two-sided test with an
alpha level of 0.05 and a beta level of 0.20. This implies that
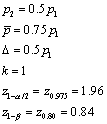
When we evaluate the sample size formula, it simplifies to
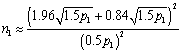
which we can rewrite as

which we round up to 50. The number of events in the second group, of
course, would be 25.
Note of attribution
These rules of thumb were originally derived by Gerald van Belle who published them on a website that was either
* www.nrcse.washington.edu/research/eo-1.html or
*
www.nrcse.washington.edu/nrcse/struts/struts.html
but these links no longer work. The new website
* www.vanbelle.org
does not mention these rules.
The rule of 16 is described in the book, Statistical Rules of Thumb. For some reason, the rule of 50 did not make it into the book or website, which is a shame because it is a very useful rule of thumb. I wrote to Dr. van Belle to ask him about this and he said that it was an oversight and that he would have to update the website with the rule of 50, but it looks like he never has. An early draft of the chapter that originally cited this rule:
* www.nrcse.washington.edu/research/struts/chapter2.pdf
also does not mention this rule.
I mentioned this omission in a book review I wrote for the second edition of Statistical Rules of Thumb:
* www.informaworld.com/smpp/section?content=a912536459&fulltext=713240928