Every data analysis should start with a descriptive or exploratory analysis. If you have no research hypotheses, then you can stop with this. If you do have research hypotheses, the analysis will provide a solid foundation for any further statistical analysis.
Here are three steps that seem to work well for many descriptive analysis:
- Know your count.
- Compute ranges and frequencies.
- Examine relationships.
These steps may not be appropriate for every analysis, but they do serve as a general guideline. In this presentation, you will see these steps applied to data from a breast feeding study, using SPSS software.
Learning objectives
In this presentation, you will learn how to:
- Organize a plan for a descriptive data analysis.
- Produce and interpret statistics for a descriptive analysis
- Examine relationships using tables and graphs.
Know your count
You need to get a feel for how much data you have. This includes the number of subjects in your study; and the number of data values that are missing. When you have a count of the number of subjects in your study, keep that in mind when you examine any statistical procedures. If the total sample size in any of these procedures is less than your count, you may have problems with an undetected missing value.
This seems like a simple thing, but often there are subtle details that you can’t ignore. For example, the following table lists the first 10 mothers in the study.
 height="347”}
height="347”}
Notice that one mother appears twice. Further investigation shows that she is the mother of twins, both of whom were enrolled in the study. In this study, there were other twins, so the full data set includes 84 infants, but only 72 mothers. The presence of twins in the study greatly complicates the analysis, but we will not discuss those complications in this presentation.
Pay very special attention to counts when you are dealing with clusters or repeated measurements. An example of clusters would be when you randomly select families of subjects. For this type of study, you should note both the number of families in the study and the number of family members in the study. An example of repeated measurements would be when you examine a patient several times. For this type of study, note both the total number of patients and the total number of exams.
Compute ranges and frequencies
You should know what the maximum and minimum values are for all the important variables in your data set. If any of these are surprising, you should investigate. You should also know how many observations fall into each level of any important categorical variables.
Our outcome measure, the age when breast feeding was stopped is a continuous variable. Here is a table of statistics for this variable, including the minimum and maximum variables.
 height="154”}
height="154”}
At first glance, the maximum value (34 weeks) seems a bit large (the study followed infants for only 24 weeks after discharge). But when I talked to the nurses involved, they explained that the length of breast feeding included the time the infants were in the hospital.
Also notice that the sample size for this table (82) is less than the total number of data points. This serves as a reminder that some of the data are missing for the age when breastfeeding was stopped
Other tables (not shown) tell us that the birth weights ranged from 1 kilogram to 2.4 kilograms and the gestational age from 26 to 36 weeks. These are reasonable values for a population of pre-term infants. The youngest and oldest mothers are 16 and 44 years old respectively, which is also quite reasonable.
Race/ethnicity is a categorical variable. Here is a table for frequencies for this variable.
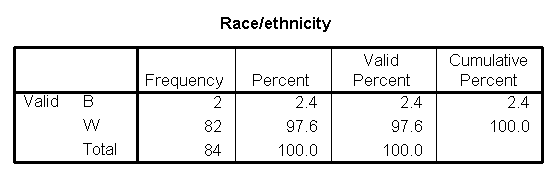 height="178”}
height="178”}
This table shows that the patient population is almost exclusively white. Not only is this valuable for writing up the description of the patient population in your research paper, it also indicates that any attempt to account for race in later models is probably a waste of time.
Examine relationships
You should have a general idea of how one variable changes as another one changes. For two categorical variables, we can examine this using crosstabs. For two continuous variables, we can examine this using a scatterplot. For a relationship between a continuous and a categorical variable, we can use boxplots.
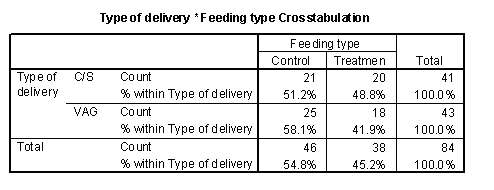
The following is a crosstabulation of feeding type versus delivery type. Notice that I have placed feeding type as the rows of the table.
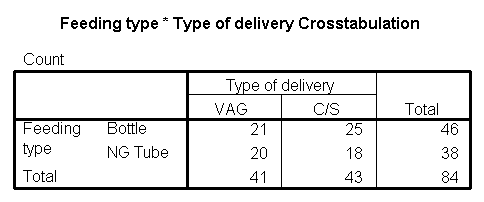 height="202”}
height="202”}
Sometimes these tables are easier to interpret with percentages. I selected the row percentages option to get the following table.
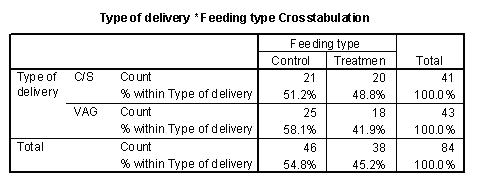
We can see that there was a roughly 50-50 change for a C-section birth to find itself in the treatment or control group. In the vaginal birhts, however, there was a slightly greater tendency to be found in the control group. This is an imbalance which might cause problems with interpretation of the results.
Does delivery type also influence duration of breast feeding? The following box plot shows that c-section births tend to have longer durations than vaginal births, a somewhat surprising finding. Because delivery type is related to both feeding type and duration of breast feeding, we should be sure to examine delivery type as a potential confounding variable in any analysis.
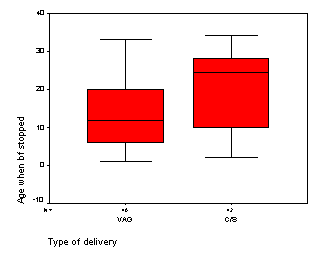 height="256”}
height="256”}
The mother’s age is an important factor in any breast feeding study. Here is a boxplot comparing ages in the two feeding groups.
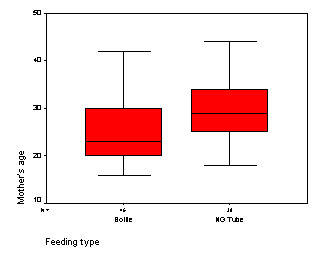 height="256”}
height="256”}
We see that the NG tube group has older mothers than the bottle group. Further statistical analysis shows that the average age is 29 in the NG tube group and 25 in the bottle group, a difference of 4 years.
We also should examine the relationship between mother’s age and duration of breast feeding. The following scatterplot shows a slight tendency for older mothers to breast feed longer.
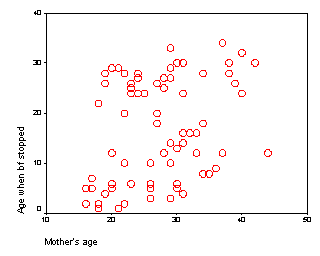 height="256”}
height="256”}
As with delivery type, we we should be careful to adjust for mother’s age in any comparison of the two feeding groups.