[Previous issue] [Next issue]
Monthly Mean newsletter, November 2009 (released 2009-12-10)
Welcome to the Monthly Mean newsletter, the newsletter that dares to call
itself average. This newsletter was sent out on December 10, 2009. If you are having
trouble reading this newsletter in your email system, please go to
www.pmean.com/news/2009-11.html. If you are not yet subscribed to this
newsletter, you can sign on at
www.pmean.com/news. If you no longer wish to receive this newsletter, there is a link to unsubscribe at the bottom
of this email. Here's a list of topics.
- Risk adjustment using the case mix index
- Power for a three arm study
- The fourth deadly sin of researchers: lust
- Monthly Mean Article (peer reviewed): Extent of publication
bias in different categories of research cohorts: a meta-analysis of empirical
studies
- Monthly Mean Article (popular press): Lack of Study Volunteers
Hobbles Cancer Fight
- Monthly Mean Book: Where's the Evidence: Debates in Modern
Medicine
- Monthly Mean Definition: What is a Kaplan-Meier survival
curve?
- Monthly Mean Quote: A few years ago, while doing a research
project...
- Monthly Mean Website: The Median Isn't the Message
- Nick News: Nicholas the iceskater
- Very bad joke: There are three types of statisticians...
- Tell me what you think.
- Upcoming statistics webinars
- Why do I do all this for free?
1. Risk adjustment using the case mix index.
In previous newsletters, I have highlighted strategies for risk adjustment:
* Analysis of covariance:
www.pmean.com/news/2009-05.hml#1, and
* Reweighting:
www.pmean.com/news/2009-07.html#2.
Another common strategy for risk adjustment is using the case mix index. Case-mix adjustment uses information at the patient level only to define
discrete groups with (hopefully) a high degree of homogeneity within the groups
and a high degree of heterogeneity between the groups.
A case-mix index (CMI) is a single number that represents the tendency for a
particular group to include patients in groups that have a higher risk (CMI > 1)
or lower risk (CMI < 1) of experiencing the large values of the outcome measure.
First, you divide the data into relatively homogenous subgroups. Then you
compute the relative weight for each subgroup, which is the average outcome
measure for all observations in that subgroup divided by the average outcome
measure for all observations across all subgroups. The case mix index is then
the sum of the weights times the size of the subgroups within a comparison unit.
I will use the same data set used in previous examples. This data set lists
average salaries for 1,184 colleges and universities in the fifty states plus
the District of Columbia. The colleges and universities are also categorized in
Divisions I, IIA, and IIB. Greater prestige and larger salaries are associated
with Division I, more moderate prestige and salaries in Division IIA, and the
lowest prestige and salaries in Division IIB. If one state pays lower salaries
than another, it may be partly due to the different mix of I, IIA, IIB in that
state compared to the rest of the United States.
The average salary across all 1,184 colleges and universities is 43 thousand
dollars. The average salaries in I, IIA, and IIB is 55, 45, and 38 thousand
dollars respectively. The case mix indexes are:
55 / 43 = 1.28 (I),
45 / 43 = 1.05 (IIA), and
38 / 43 = 0.88 (IIB).
You might think of this along the lines of the famous quote in �Animal Farm�
by George Orwell (All animals are equal but some animals are more equal than
others). A Type I school is �worth� more (about 28% more) than an average school
because that�s how much larger the salaries are (on average). A Type IIB school
is worth less (about 12% less) because its salaries are lower (on average).
West Virginia (WV) has lower average salaries, but also a far larger number
of IIB colleges and universities. The CMI for WV is
1.28*0.06 = 0.08
1.05*0.06 = 0.06
0.88*0.88 = 0.77
----
0.91.
This value is less than one, which indicates that WV has a case mix that
tends to produce artificially low salaries. Divide the unadjusted average salary
in WV by the CMI to get an adjusted
average salary for WV
35 / 0.91 = 38.5.
The salary for WV still lags behind the overall average, but not by as much
as the raw data might indicate. Dividing by 0.91 adjusted the estimate upward to
compensation for the larger proportion of IIB schools.
The CMI for DC is
1.28*0.56 = 0.72
1.05*0.22 = 0.23
0.88*0.22 = 0.19
----
1.14.
The CMI is greater than one, which indicates that DC has a case mix that
tends to produce artificially high salaries. Divide by CMI to get an adjusted
salary for DC
50 / 1.14 = 43.9.
What are the strengths and weaknesses of case mix adjustment? Case mix
adjustment is very simple and can be done with a spreadsheet program if you
desire. It cannot incorporate adjustments for continuous covariates. This method
also can only adjust for variables that are imbalanced across the groups.
There are still other approaches to risk adjustment, such as propensity scores, that I will discuss in future newsletters. This
work was part of a project I am helping with: the adjustment of outcome measures
in the National Database of Nursing Quality Indicators. The work described in
this article was supported in part through a grant of the American Nursing
Association.
2. Power for a three-arm study
Someone asked for advice on how to calculate power for a three arm study. The
outcome measure in this experiment is binary. For a two-arm study, the power
calculation is easy. Just use the formula for power for a test comparing two
proportions.
You could do this here as well, and demonstrate that the power for the three
possible comparisons (1 vs 2, 1 vs 3, 2 vs 3) among the proportions is at least
80%. But a more formal calculation would use the Chi-squared test statistic.
For a chisquare test, you need to estimate the non-centrality parameter by
creating some fake data that corresponds to the proportions of yes/no in each
group that you think represents a clinically relevant shift. For example, you
might hypothesize that if arms 1, 2, and 3, have proportions 0.2, 0.3, and
0.4, that you would have to have to look at a chisquare statistic for a table
that looks something like
20 80
30 70
40 60
The expected counts here would be
30 70
30 70
30 70
and the chisquare statistic for this artificial setting would be
10^2/30+10^2/70+0^2/30+0^2/70+10^2/30+10^2/70 = 9.52
That's your noncentrality parameter, assuming 100 patients per group, 300
patients total.
Here's how you would enter the data into a Java applet for power written by
Dr. Russ Lenth.
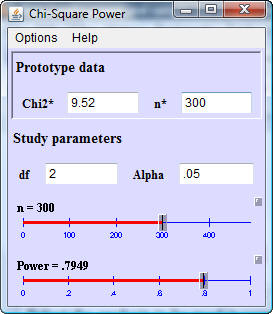
In this dialog box, Chi2* represents the noncentrality parameter using an
idealized data set and n* is the total sample size in your idealized data set.
In this situation, the power for a total sample size of 300 is almost 80%. If
the sample size were decreased to 200, the power would decrease to 61%
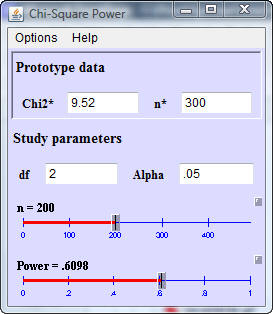
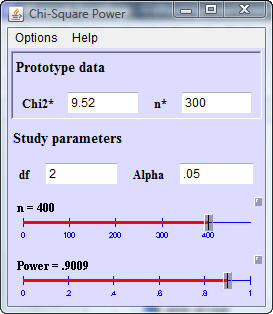
and if the total sample size were increased to 400, the power would increase
to 90%.
You can find Dr. Lenth's free Java power applets at
*
www.cs.uiowa.edu/~rlenth/Power/
Additional discussion of this example, including screenshots from another
free power calculation program, G*Power, is available at
*
www.pmean.com/09/ThreeArmPower.html
3. The fourth deadly sin of researchers: lust
The fourth deadly sin of researchers is lust. Many researchers desire fame and recognition, and while this is often a
positive motivating factor, sometimes this desire turns to a lust for
recognition that can distort and harm the research process.
Duplicate publication. In order to let each author get his/her place in the
sun, researchers will publish the same data twice, with different lead authors,
and no hint in the publications that the data were published elsewhere. This is
a serious problem for meta-analysis, as it can lead to double counting of some
research results.
Aversion to multi-center trials. In a belief that being a big fish in a small
pond is better than being a small fish in a big pond, researchers would prefer
being first author on a small single center study than fifth author on a large
multi-center study. Since each single center study uses a slightly different
protocol, the meta-analysts have to cope with a greater degree of heterogeneity
in the research results.
Use of the least publishable unit. In an attempt to pad the number of
publications to meet a quota for tenure or promotion, researchers may try to
break their research into the smallest pieces possible and submit each piece to
a separate journal. This leads to a fragmentary perspective on a research topic.
There are some arguments in favor of publishing small articles, especially for
younger faculty, but this is often taken too far.
Outright fraud. While many cases of research fraud involve money, others
involve non-monetary rewards, such as fame and recognition. I'll admit that I
get a big thrill when I see my name in print, or when I get an invitation to
talk at a research conference. This desire for fame has caused some people to
make up data. It helps if you make-up the right type of data, data that supports
hypotheses that scientists suspect, but where getting actual data on these
hypotheses is hard.
In previous newsletters, I have highlighted some of the other deadly sins of
researchers:
* gluttony, www.pmean.com/news/2009-09.html#2,
* sloth, www.pmean.com/news/2009-07.html#3, and
* pride www.pmean.com/news/2000-05.html#2.The remaining three sins of researchers (wrath,
greed, and envy) will be
described in future issues of this newsletter.
4. Monthly Mean Article (peer reviewed): Extent of
publication bias in different categories of research cohorts: a meta-analysis of
empirical studies
Fujian Song, Sheetal Parekh-Bhurke, Lee Hooper, et al. Extent of
publication bias in different categories of research cohorts: a meta-analysis
of empirical studies. BMC Medical Research Methodology. 2009;9(1):79.Abstract:
"BACKGROUND: The validity of research synthesis is threatened if published
studies comprise a biased selection of all studies that have been conducted.
We conducted a meta-analysis to ascertain the strength and consistency of the
association between study results and formal publication. METHODS: The Cochrane
Methodology Register Database, MEDLINE and other electronic bibliographic
databases were searched (to May 2009) to identify empirical studies that
tracked a cohort of studies and reported the odds of formal publication by
study results. Reference lists of retrieved articles were also examined for
relevant studies. Odds ratios were used to measure the association between
formal publication and significant or positive results. Included studies were
separated into subgroups according to starting time of follow-up, and results
from individual cohort studies within the subgroups were quantitatively
pooled. RESULTS: We identified 12 cohort studies that followed up research from
inception, four that included trials submitted to a regulatory authority, 28
that assessed the fate of studies presented as conference abstracts, and four
cohort studies that followed manuscripts submitted to journals. The pooled
odds ratio of publication of studies with positive results, compared to those
without positive results (publication bias) was 2.78 (95% CI: 2.10 to 3.69) in
cohorts that followed from inception, 5.00 (95% CI: 2.01 to 12.45) in trials
submitted to regulatory authority, 1.70 (95% CI: 1.44 to 2.02) in abstract
cohorts, and 1.06 (95% CI: 0.80 to 1.39) in cohorts of manuscripts.
CONCLUSIONS: Dissemination of research findings is likely to be a biased
process. Publication bias appears to occur early, mainly before the
presentation of findings at conferences or submission of manuscripts to
journals." [Accessed November 29, 2009]. Available at:
www.biomedcentral.com/1471-2288/9/79.
5. Monthly Mean Article (popular press): Lack of Study
Volunteers Hobbles Cancer Fight
Gina Kolata. Lack of Study Volunteers Hobbles Cancer Fight. The New
York Times. 2009. Excerpt: "There are more than 6,500 cancer clinical trials
seeking adult patients, according to clinicaltrials.gov, a trials registry. But
many will be abandoned along the way. More than one trial in five sponsored by
the National Cancer Institute failed to enroll a single subject, and only half
reached the minimum needed for a meaningful result, Dr. Ramsey and his colleague
John Scoggins reported in an editorial in the September 2008 issue of The
Oncologist." [Accessed August 29, 2009]. Available at:
www.nytimes.com/2009/08/03/health/research/03trials.html.
6. Monthly Mean Book: Where's the evidence? Controversies
in modern medicine
William A Silverman. Where's the evidence? Controversies in modern
medicine. New York: Oxford University Press Excerpt: "Medicine is moving
away from reliance on the proclamations of authorities to the use of numerical
methods to estimate the size of effects of its interventions. But a rumbling
note of uneasiness underlines present-day medical progress: the more we know,
The more questions we encounter about what to do with the hard-won information.
The essays in Where's the Evidence examine the dilemmas that have arisen as the
result of medicine's unprecedented increase in technical powers. How do doctors
draw the line between "knowing" (the acquisition of new medical information) and
doing" (the application of that new knowledge)? What are the long-term
consequences of responding to the demand that physicians always do everything
that can be done? Is medicine's primary aim to increase the length of life? Or
is it to reduce the amount of pain and suffering? And who is empowered to choose
when these ends are mutually exclusive? This engaging collection of essays will
be of interest to professionals interested in the evidence-based medicine
debate, including epidemiologists, neonatologists, those involved in clinical
trials and health policy, medical ethicists, medical students, and trainees."
Available at: lccn.loc.gov/97052058.
7. Monthly Mean Definition: What is a Kaplan-Meier
survival curve?
The Kaplan-Meier (KM) survival curve is a graphical display of the estimated
probability that an event will occur. This explanation will focus on mortality,
but there is nothing about a KM curve that requires the event to be an actual
death. Other events, such as relapse or re-hospitalization, can also be
displayed using KM. The KM curve is not restricted to events occurring in people
but can also assess things like the failure of medical devices. Finally, the KM
curve does not always have to summarize gloomy events. Time to positive events,
such as pregnancy, can also be evaluated using a KM curve.
The KM curve can handle dropouts, patients who provide information during
part of the study but who leave prior to experiencing the event. It's kind of
like that joke about the couple who were both in their nineties who go to a
lawyer asking for help getting a divorce. The lawyer looks surprised, and asks
how long they've been married. Sixty years, the husband replied, and we've been
miserable for all sixty years. The wife nodded in agreement. The lawyer asked,
if you've been miserable all this time, why have you waited so long to get a
divorce. The wife sighed and said, we wanted to wait until all of the children
were dead.
Researchers can't wait until all of the patients in a study have died before
they publish results of a mortality study. It would take too long. There are
also problems with patients who leave town and don't provide a forwarding
address. The term censoring is used to describe patients who are known to have
survived for at least a certain amount of time, but the actual date of their
death is unknown other than being beyond the time they were evaluated.
Consider a hypothetical experiment involving mortality in a sample of 25
fruit flies. The researcher diligently records the day of death for each fruit
fly. The first fly dies on day 37, the second on day 42, and so forth. The
researcher gets the number of days of life for 15 of the 25 flies, but one day,
the experimenter leaves the cover off of the container. The ten remaining fruit
flies buzz off and are never seen again. You might think that the experiment is
ruined, but you can still salvage some of the data. You have the days of life
for the first fifteen flies, and the 13th provides information about the median
survival time.
The information about censored observations needs to be incorporated
carefully in the analysis, and you have to assume that the fact that a patient
was lost to follow-up is independent of their prognosis. If a patient drops out
because they are flying to Mexico for laetrile treatments is going to be
problematic. No one with a good prognosis flies to Mexico for laetrile.
The KM curve is frequently used to compare survival in two or more groups. We
can look for gaps in these curves in a horizontal or vertical direction. A
vertical gap means that at a specific time point, one group had a greater
fraction of subjects surviving. A horizontal gap means that it took longer for
one group to experience a certain fraction of deaths. Here's a nice example of a
KM curve published in an open source journal (Bachmann et al. BMC Cancer 2009
9:255 doi:10.1186/1471-2407-9-255,
www.biomedcentral.com/1471-2407/9/255/figure/F2).
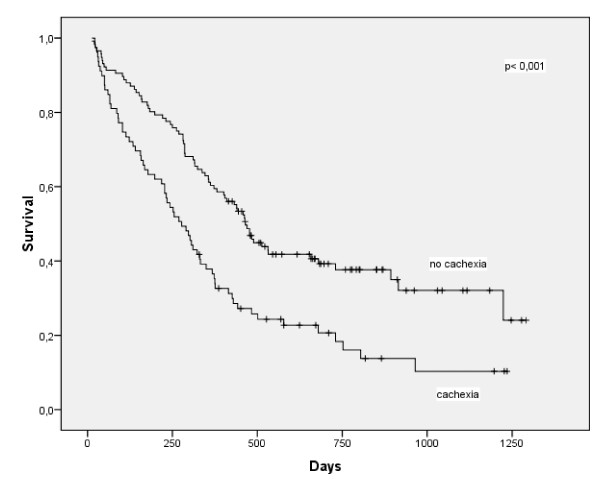
Here's an example of a KM curve comparing survival of patients with cachexia
to patients without cachexia.
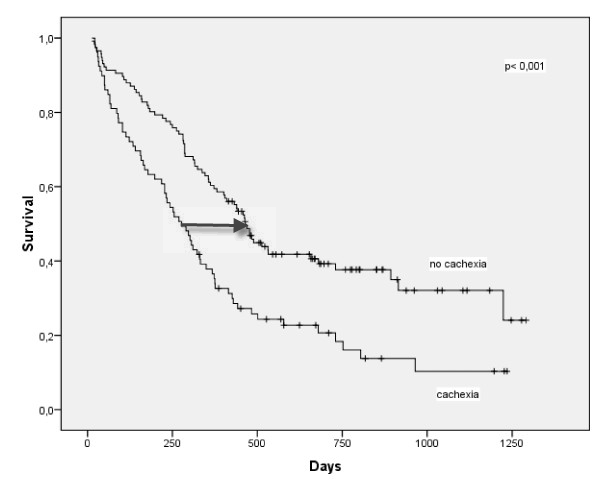
Notice a pronounced gap in the horizontal direction. The median survival time
is much larger (about 200 days larger) in the patients without cachexia.
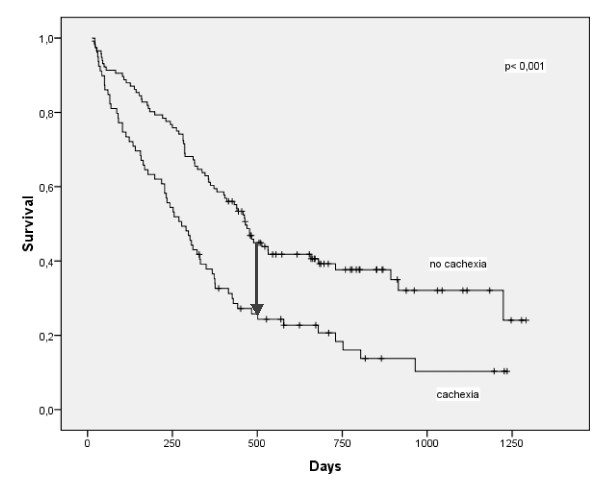
There is also a pronounced gap in the vertical direction. At 500 days, the
probability of survival is about 45% in the patients without cachexia and only
25% in the patients with cachexia.
I wrote a nice description of the Kaplan-Meier curve in Chapter 6 of my book,
Statistical Evidence. I'm working on some updates of this description as well as
updates on material from my old website.
8. Monthly Mean Quote: A few years ago, while doing a
research project...
A few years ago, while doing a research project, I measured several
different hormones in about 30 subjects. One subject's growth hormone levels
came back about 100 times higher than everyone else's. I assumed this was a
transcription error, so I moved the decimal point two places to the left. Some
weeks later, I met the technician who had analysed the specimens and he asked,
"Whatever happened to that chap with acromegaly?" Trish Greenhalgh,
www.bmj.com/cgi/content/full/315/7104/364.
9. Monthly Mean Website: The Median Isn't the Message
The Median Isn't the Message by Stephen Jay Gould and Prefatory
Note by Steve Dunn. Description: This is a classic treatise that anyone
researching their own illness should read. Dr. Dunn's comments are spot on. "As
far as I'm concerned, Gould's The Median Isn't the Message is the wisest, most
humane thing ever written about cancer and statistics. It is the antidote both
to those who say that, "the statistics don't matter," and to those who have the
unfortunate habit of pronouncing death sentences on patients who face a
difficult prognosis. Anyone who researches the medical literature will confront
the statistics for their disease. Anyone who reads this will be armed with
reason and with hope." [Accessed November 19, 2009]. Available at:
cancerguide.org/median_not_msg.html
10. Nick News: Nicholas the iceskater
One of the local shopping centers has an ice rink and they just opened for
the season. Nicholas, who had only skated on ice once before, stepped bravely
out and started skating like a pro.

You can find additional pictures at
*
www.pmean.com/personal/iceskater.html
Also note a picture of Nicholas smile with several big gaps in it at
*
www.pmean.com/personal/toothfairy.html
11. Very bad joke: There are three types of
statisticians...
There are three types of statisticians in the world, those who can count
and those who can't.
This is a classic joke told with economists, accountants, etc. in place of
statisticians. There are so many citations like this on google, that I can't
pick out one. A cute variation on this for the programming geeks among you is
There are 10 types of programmers in the world, those who understand
binary and those who don't.
12. Tell me what you think.
Thank you for taking the time to provide feedback for the November 2009 issue
of the Monthly Mean. Your responses will be kept anonymous. I have three short open ended questions at
*
https://app.icontact.com/icp/sub/survey/start?sid=6190&cid=338122
You can also provide feedback by responding to this email. My three
questions are:
- What was the most important thing that you learned in this newsletter?
- What was the one thing that you found confusing or difficult to follow?
- What other topics would you like to see covered in a future newsletter?
Three people provided feedback to the last newsletter. I got praise for the
article on rounding and re-ordering and the article on early stopping of a study
and general praise for the newsletter. The only concern was about the basic
formatting. I don't know what this means and I'd appreciate additional
information from the person who left this comment or anyone else. Topics
suggested for future newsletters include longitudinal analysis and robust
analysis. I have been intending to write up a series of webpages about
longitudinal analyses, but it's a complicated area and takes a lot of time to
develop. I do hope to have something soon about this.
13. Upcoming statistics webinars
Free to all! What do all these numbers
mean? Odds ratios, relative risks, and number needed to treat, Thursday,
December 17, 2009, 11am-noon, CST. Abstract: This one hour training class will teach you some of the
numbers used in studies where the outcome only has two possible values (e.g.,
dead/alive). The odds ratio and the relative risk are both measures of risk
used for binary outcomes, but sometimes they can differ markedly from one
another. The relative risk offers a more natural interpretation, but certain
research designs preclude its computation. Another measure of risk, the number
needed to treat, provides comparisons on an absolute rather than relative
scale and allow you to assess the trade-offs between effects and harms. No statistical experience is
necessary.
To register, send an email to
with the words "December 17 webinar" in the subject line. A draft handout is
available below. The link to the official handout will appear here 24 hours
prior to the webinar.
Free to all! The first three steps in a
descriptive data analysis, with examples in PASW/SPSS, Thursday, January
21, 2010, 11am-noon, CST. Abstract: This one hour training class will give you a
general introduction to descriptive data analysis using PASW (formerly known as SPSS)
software. The first three steps in a descriptive data analysis are: (1) know
how much data you have and how much data is missing; (2) compute ranges or
frequencies for individual variables; and (3) compute crosstabs, boxplots, or
scatterplots to examine relationships among pairs of variables. This class is
useful for anyone who needs to analyze research data. No statistical experience
or knowledge about PASW/SPSS is
necessary.
To register, send an email to
with the words "January 21 webinar" in the subject line. A draft handout
is available below. The link to the official handout will appear here 24 hours
prior to the webinar.
14. Why do I do all this for free?
I write this newsletter and offer free statistics webinars partly for fun
and partly to build up goodwill for my consulting business,
www.pmean.com/consult.html.
Unfortunately, I have not had much success in publicizing these efforts; after
one year, I only have 148 subscribers. If you like what I write, please
forward this email to others you know who might also find my work interesting.
There's a link at the bottom of this newsletter that makes forwarding easy. My
goal is to have 1,500 subscribers by the end of 2010, and I can only meet that
goal with your help.
What now?
Sign up for the Monthly
Mean newsletter
Review the archive of
Monthly Mean newsletters
Go to the main page of
the P.Mean website
Get help
 This work is
licensed under a Creative
Commons Attribution 3.0 United States License. This page was
written by Steve Simon and was last modified on
2017-06-15.
Need more information? I have a page with general help resources.
You can also browse for pages similar to this one at Category: Website
details.
This work is
licensed under a Creative
Commons Attribution 3.0 United States License. This page was
written by Steve Simon and was last modified on
2017-06-15.
Need more information? I have a page with general help resources.
You can also browse for pages similar to this one at Category: Website
details.