There was a discussion on EDSTAT-L about studies with too much power and precision. You can indeed have too much power/precision, and here is a pragmatic example. I was asked to do an audit of records where we overbilled. The cost of reviewing all the records was prohibitive. So my proposal was to randomly select records and then pay back at a rate corresponding to the upper 95% confidence limit of the average overbilled amount times the actual number of records where we overbilled. Equivalently, you could say this product is a confidence interval on the total overbilling.
The ideal sample size in such a setting is the sample size where the cost of collecting an additional record outweighs the resulting gain in precision. Here's a graph showing the gain in precision as we add an additional observation to the data set, assuming a 95% one sided confidence interval, a standard deviation of 50, a cost of $100 per sampled record, and a total population of 500 records.
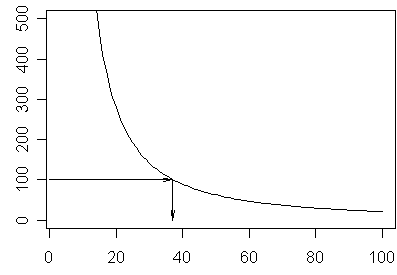
At about 37 records, the change in precision is about $100. If you sampled more than this value, you would be spending more on the additional sampling costs than you would save by reducing the uncertainty in your estimate.
From a theoretical perspective, patients who enroll in a clinical trial are making sacrifices to be part of the trial. At a minimum, there is an inconvenience factor (a lost Saturday morning when they could be watching Sponge Bob). Sometimes they will undergo a painful event, such as a blood draw or a spinal tap. In some clinical trials, they may endure an increase in risk (hopefully only a minimal risk, of course). It is unfair to ask more patients to make those sacrifices than you need to produce reasonable precision for your confidence interval.
It gets even more serious when your clinical trial has a placebo arm. Asking more patients than necessary to take a placebo is a very serious ethical concern.
Now if you are talking about a retrospective chart review, the issue is moot. I don't care if a retrospective chart review has too much power and precision, because nobody is making extra sacrifices to help you do your research, other than the poor person who has to review all those medical charts.
In theory, all sample size justifications are based on economic considerations. Improvements in precision are worth something to you, so attach a value to this (not an easy thing to do, but in theory it can be done). Now tally up all the costs associated with the study: direct costs to the study budget as well as indirect costs associated with the inconvenience, pain, etc., that each patient has to endure. Again this is not an easy thing to do. The optimal sample size is one where the incremental value of improved precision is offset by the direct and indirect costs of obtaining an additional patient. No one does it this way, but they should.