[Previous issue] [Next issue]
[The Monthly Mean] April 2010--Even I get confused about p-values

You are viewing an early draft of the Monthly Mean newsletter for
April 2010. I hope to send this newsletter out sometime in late April.
Welcome to the Monthly Mean newsletter for April 2010. If you are having
trouble reading this newsletter in your email system, please go to
www.pmean.com/news/201004.html. If you are not yet subscribed to this
newsletter, you can sign on at
www.pmean.com/news. If you no longer wish to receive this newsletter, there is a link to unsubscribe at the bottom
of this email. Here's a list of topics.
Lead article: Even I get confused about p-values
2. The sixth deadly sin of researchers: Envy
3. I only got a 20% response rate, but at least my confidence
interval was narrow
4. Monthly Mean Article (peer reviewed): Can we rely on the best
trial? A comparison of individual trials and systematic reviews
5. Monthly Mean Article (popular press): Convincing the Public to
Accept New Medical Guidelines
6. Monthly Mean Book: Damned Lies and Statistics
7. Monthly Mean Definition: What is a forest plot?
8. Monthly Mean Quote: The statistician who supposes...
9. Monthly Mean Unsung Hero Award: Steven Strogatz
10. Monthly Mean Website: Common Mistakes in Statistics
11. Nick News: Stuff about me this month instead of about
Nicholas
12. Very bad joke: A researcher is finishing up...
13. Tell me what you think.
14. Upcoming statistics webinars
15. Join me on Facebook and LinkedIn
1. Even I get confused about p-values
In one of my webinars, I offered the following quiz question:
A research paper computes a p-value of 0.45. How would you interpret this
p-value?
- Strong evidence for the null hypothesis
- Strong evidence for the alternative hypothesis
- Little or no evidence for the null hypothesis
- Little or no evidence for the alternative hypothesis
- More than one answer above is correct.
- I do not know the answer.
This is actually a bit of a trick question. It wasn't intended as a trick
question; I was asleep at the switch when I wrote this. Still, it's like when
my seven year old son makes a mistake--this really represents a learning
opportunity.
Let's review what a p-value is. I define a p-value as a measure of evidence
(some might disagree with this definition, by the way). It is a measure of how
much evidence we have against the null hypothesis. If the p-value is small, we
have lots of evidence against the null hypothesis. If the p-value is large, we
have little or no evidence against the null hypothesis.
A more conventional approach is to define the p-value as the probability of
getting a particular result from a sample, or a result more extreme, assuming
the null hypothesis is true. Again, this definition raises some controversy: why
are we looking at results more extreme; these are results that are not observed
in the sample.
Even the definition of the null hypothesis is controversial. The null
hypothesis is the hypothesis of no effect, or no difference. It states, just to
cite one example, that the difference in means between two groups is exactly
zero. Does anyone actually believe that two populations could ever have EXACTLY
the same mean, down to the very last decimal place?
Put all these controversies aside for now. The p-value is certainly
the most commonly cited statistic in medical journals and even if you dislike
how or why it is computed, you can't survive in the current world of research
without it.
The important thing to recognize is that the p-value is backwards in couple
of ways. First,
* it is a small p-value that represents lots of evidence, and
* it is a large p-value that represents little or no evidence.
Second,
* the p-value represents evidence AGAINST a hypothesis,
* it never represents directly evidence FOR a hypothesis.
A large p-value, by itself, does not help very much. If you see a large
p-value in a research study, look for some corroborating evidence, such as a
power calculation that was conducted prior to data collection. Also look for a
very narrow confidence interval. With one or both of these pieces of corroboration, a
large p-value can be taken as strong evidence in favor of the null hypothesis.
In contrast, if no power calculation was done, and if the confidence
intervals in a study are wide enough to drive a truck through, then a large
p-value may just be telling you that the sample size is much too small to draw
any firm conclusions.
Let's return to the quiz question. This p-value is large, so we do not reject the null hypothesis.
So we can rule out #2 right away. But how about #1? We sometimes say when the
p-value is large that we "accept the null hypothesis." But
purists will insist on the wording "fail to reject the null hypothesis."
A large p-value means little or no evidence against the null hypothesis,
but you should not automatically interpret it as lots of evidence for the null
hypothesis. It may be that your sample size is so small that you have little
evidence for ANY hypothesis. Without some sort of context, such as an a priori
sample size justification, we can't really say too much. With that sample size
justification, #1 would be a good answer. But without it, it is possible that
we can't decide between #1 and #3. If we know that the sample size is much too
small then both #3 and #4 are correct.
But really, #6 is indeed the correct answer, though I can't be too upset
with people who choose #1 or #4 or even #3 (which sort of makes #5 an
attractive choice). Without more context, you cannot say anything with
assurance about a large p-value. If I had provided more information, you could
have chosen a specific answer, perhaps, but I didn't give you that extra
information.
Here's how I'll word it in future webinars.
A research paper computes a p-value of 0.45. How would you interpret this
p-value?
- Strong evidence for the null hypothesis
- Strong evidence for the alternative hypothesis
- Strong evidence against the null hypothesis
- Strong evidence against the alternative hypothesis
- A large p-value, by itself, does not provide strong evidence for or
against any hypothesis.
- I do not know the answer.
Clearly, answer #5 is the one I am looking for. I do apologize to the poor
folks at the webinar who had to wrestle with a trick question.
2. The sixth deadly sin of researchers: Envy
Envy or jealousy can pop up in research when authors fail to include
important references of previous work in their biographies. It is hard to find
empirical data to quantify the deficiencies of the typical biography, but there
is a lot of commentary that this is a serious problem.
One reason that authors may fail to cite previous work is an effort to make
their own work look more original. Perhaps there is also a sense of competition
among researchers, and this makes one group reluctant to highlight the work of
other groups. A third reason is that authors may be unwilling to cite competing
research that might possibly sway readers to a different conclusion than the
ones the authors believe.
Envy can also lead scientists to limit access to materials and data produced
by their research. While some limits may be appropriate for reasons of privacy,
or because papers using the materials and data are still in the publication
pipeline, too often limits on sharing are based on more selfish motives.
3. I only got a 20% response rate, but at least my
confidence interval was narrow
Someone wanted advice on how to diffuse critics of his/her survey. The survey
only had a 20% response rate, but the confidence interval was pretty good
(plus/minus 2.8%). I'm afraid that my advice wasn't too helpful.
Generally, you should strive for a 90% percent response rate. Anything less than
70% response rate is suspect.
Now I realize that almost all survey research has a lower response rate than
70%. That doesn't excuse you. If all your friends jumped off a cliff would you
jump off also?
With a low response rate, the only thing that can salvage your analysis is
data to show that those who did not respond to your survey have similar
demographics to those who did respond. There are several ways this could happen.
Sometimes you get data in "waves". Some of your surveys are returned immediately
and others are returned only after a reminder letter is sent. If the
demographics of the first and second waves are similar, then it is not too much
of an extrapolation to expect the demographics to be similar as well for the remainder of the surveys
(those which might have been sent in with more reminders as well as those that
were fated to never be sent in no matter how much you nagged).
Sometimes you have partial information that can help. If you can show, for
example, that the response rates are fairly uniform across zip codes, that's a
good sign.
These approaches help somewhat, but with a low response rate there will
always be a nagging doubt in many people's minds that there was something that
you missed that might be an important source of bias.
A narrow confidence interval, however, does not prove that a 20% response
rate was all right. Low response rates create a biased sample and confidence
intervals, for the most part, do not reflect the uncertainties caused by biased
samples.
There's a story about a student who ran a small research project to see if
people were willing to share information on the Internet. That student collected
data using, you guessed it, an Internet survey. And the results were that people
liked sharing information on the Internet. Now how many people, do you think,
who find the Internet irritating or inconvenient, would take the time to fill
out this Internet survey?
There are ways to run Internet surveys well, but this student did not
employ any of those ways. The data from that project is probably worthless
(except perhaps as an example of what not to do). But I bet the confidence
interval still looked pretty good.
4. Monthly Mean Article (peer reviewed): Can we rely on
the best trial? A comparison of individual trials and systematic reviews
Paul Glasziou, Sasha Shepperd, Jon Brassey. Can we rely on the best trial?
A comparison of individual trials and systematic reviews. BMC Medical
Research Methodology. 2010;10(1):23. Abstract: "BACKGROUND: The ideal
evidence to answer a question about the effectiveness of treatment is a
systematic review. However, for many clinical questions a systematic review will
not be available, or may not be up to date. One option could be to use the
evidence from an individual trial to answer the question? METHODS: We assessed
how often (a) the estimated effect and (b) the p-value in the most precise
single trial in a meta-analysis agreed with the whole meta-analysis. For a
random sample of 200 completed Cochrane Reviews (January, 2005) we identified a
primary outcome and extracted: the number of trials, the statistical weight of
the most precise trial, the estimate and confidence interval for both the
highest weighted trial and the meta-analysis overall. We calculated the p-value
for the most precise trial and meta-analysis. RESULTS: Of 200 reviews, only 132
provided a meta-analysis of 2 or more trials, with a further 35 effect estimates
based on single trials. The average number of trials was 7.3, with the most
precise trial contributing, on average, 51% of the statistical weight to the
summary estimate from the whole meta-analysis. The estimates of effect from the
most precise trial and the overall meta-analyses were highly correlated (rank
correlation of 0.90).There was an 81% agreement in statistical conclusions.
Results from the most precise trial were statistically significant in 60 of the
167 evaluable reviews, with 55 of the corresponding systematic reviews also
being statistically significant. The five discrepant results were not strikingly
different with respect to their estimates of effect, but showed considerable
statistical heterogeneity between trials in these meta-analyses. However, among
the 101 cases in which the most precise trial was not statistically significant,
the corresponding meta-analyses yielded 31 statistically significant results.
CONCLUSIONS: Single most precise trials provided similar estimates of effects to
those of the meta-analyses to which they contributed, and statistically
significant results are generally in agreement. However, "negative" results were
less reliable, as may be expected from single underpowered trials. For
systematic reviewers we suggest that: (1) key trial(s) in a review deserve
greater attention (2) systematic reviewers should check agreement of the most
precise trial and the meta analysis. For clinicians using trials we suggest that
when a meta-analysis is not available, a focus on the most precise trial is
reasonable provided it is adequately powered." [Accessed April 20, 2010].
Available at:
*
www.biomedcentral.com/1471-2288/10/23.
5. Monthly Mean Article (popular press): Convincing the
Public to Accept New Medical Guidelines
Christie Aschwanden. Convincing the Public to Accept New Medical
Guidelines. Miller-McCune Magazine. 2010. Excerpt: "A $1.1 billion
provision in the federal stimulus package aims to address the issue by providing
funds for comparative effectiveness research to find the most effective
treatments for common conditions. But these efforts are bound to face resistance
when they challenge existing beliefs. As Nieman and countless other researchers
have learned, new evidence often meets with dismay or even outrage when it
shifts recommendations away from popular practices or debunks widely held
beliefs. For evidence-based medicine to succeed, its practitioners must learn to
present evidence in a way that resonates. Or, to borrow a phrase from politics,
it�s not the evidence, stupid � it�s the narrative." [Accessed April 20,
2010]. Available at:
*
www.miller-mccune.com/health/convincing-the-public-to-accept-new-medical-guidelines-11422/.
6. Monthly Mean Book: Damned Lies and Statistics
Damned Lies and Statistics, Joel Best (2001), Berkeley CA: University
of California Press. ISBN: 9780520219786
This is one of my favorite books and one I recommend to anyone. It is easy to
read and has a very important message. An excerpt from the book's website
*
www.ucpress.edu/books/pages/9358.php
provides a nice general description of the book: "This accessible book
provides an alternative to either naively accepting the statistics we hear or
cynically assuming that all numbers are meaningless. It shows how anyone can
become a more intelligent, critical, and empowered consumer of the statistics
that inundate both the social sciences and our media-saturated lives."
But most of the other comments miss the mark. Here's a paragraph from the
book itself that gets at Dr. Best's most important viewpoint. "Social
statistics describe society, but they are also products of our social
arrangements. The people who bring social statistics to our attention have
reasons for doing so; they inevitably want something, just as reporters and the
other media figures who repeat and publicize statistics have their own goals.
Statistics are tools, used for particular purposes. Thinking critically about
statistics requires understanding their place in society."
He argues that you have to look at the context in which a statistic was
derived. That reminds me strongly of arguments made by postmodern philosophers,
but Dr. Best doesn't suffer from the excesses of such a philosophy. Even though
you can't separate a statistic from the social context that created it, he still
values these numbers. "Debates about social problems routinely raise
questions that demand statistical answers: Is the problem widespread? How many
people--and which people--does it affect? Is it getting worse? What does it cost
society? What will it cost to deal with it? Convincing answers to such questions
demand evidence, and that usually means numbers, measurements, statistics."
Finally, Dr. Best is not out to skewer any particular social institution.
"While we may be more suspicious of statistics presented by people with whom we
disagree--people who favor different political parties or have different
beliefs--bad statistics are used to promote all sorts of causes. Bad statistics
come from conservatives on the political right and liberals on the left, from
wealthy corporations and powerful government agencies, and from advocates of the
poor and the powerless. In this book, I have tried to choose examples that show
this range: I have selected some bad statistics used to justify causes I
support, as well as others offered to promote causes I oppose. I hope that you
and everyone else who reads this book will find at least one discomforting
example of a bad statistic presented in behalf of a cause you support. Honesty
requires that we recognize our own errors in reasoning, as well as those of our
opponents."
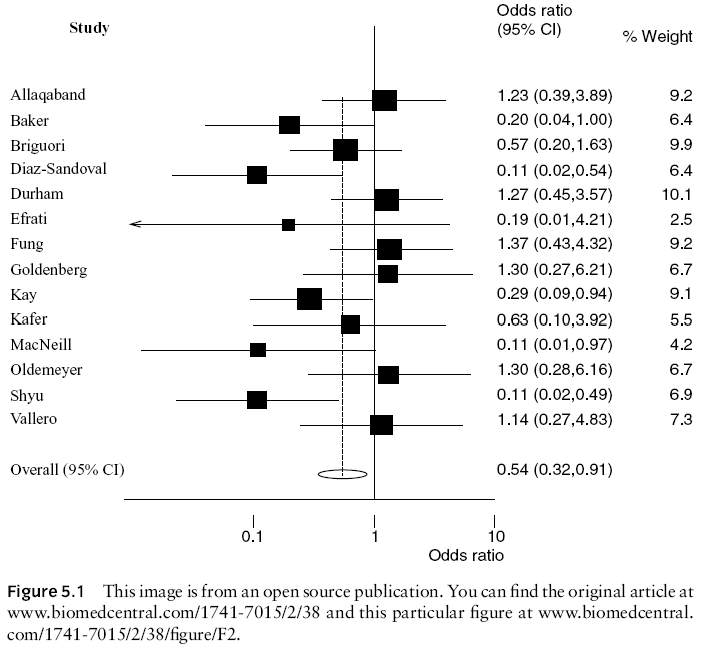
7. Monthly Mean Definition: What is a forest plot?
The forest plot provides a graphical summary of the quantitative findings of
a group of studies, typically a group of studies that are part of a
meta-analysis or systematic overview. In a forest plot, individual studies are
arranged from the top of the graph to the bottom. For each individual study, a
square is drawn on the horizontal axis corresponding to the point estimate of
the outcome in that study (e.g, standardized difference in means, log odds
ratio). The size of the square represents weight associated with that estimate.
Horizontal lines are drawn to upper and lower confidence limits.
This plot can be used to evaluate heterogeneity. Look for marked departures
from a normal random scatter such as:
* most studies cluster together, with one or two
outlying studies (but okay if outlying studies have small sample sizes).
* bimodal
patterns (e.g., half the studies show a strong effect, half show little or no
effect).
Here's an example of a forest plot, taken from chapter 5 of my book, and
originally taken from an open source journal,
8. Monthly Mean Quote: The statistician who supposes...
The statistician who supposes that his main contribution to the planning of an
experiment will involve statistical theory, finds repeatedly that he makes his most
valuable contribution simply by persuading the investigator to explain why he wishes to
do the experiment, by persuading him to justify the experimental treatments, and to
explain why it is that the experiment, when completed, will assist him in his research.
-- Gertrude M. Cox. (I can't recall the original source where I
found this quote. Sorry!)
9. Monthly Mean Unsung Hero Award: Steven Strogatz
Steven Strogatz has been posting an amazing series of mathematical articles
on the New York Times website that talks about fundamental aspects of
mathematics (starting with whole numbers and currently discussing integration).
These articles are delightfully fun to read and very accessible, even to
non-mathematicians. You can find all of his articles at
*
http://opinionator.blogs.nytimes.com/author/steven-strogatz/
10. Monthly Mean Website: Common Mistakes in Statistics
Martha Smith. Common Mistakes in Statistics. Excerpt: "Medical
researcher John P. A. Ioannidis has asserted, "It can be proven that most
claimed research findings are false."[1]. There are some criticisms of his
"proof"[2], but even most of his critics agree that there is a high incidence of
false conclusions in research papers. Indeed, we frequently hear in the news
results of a research study that appears to contradict the results of a study
published just a few years ago. Although there is occasional deliberate
falsification, most of the problem comes from lack of understanding of
statistical techniques, their proper use, and their limitations. The intent of
this website is to discuss some of the common mistakes made in using statistics,
and offer suggestions on how to avoid making them." [Accessed April 9,
2010]. Available at:
*
www.ma.utexas.edu/users/mks/statmistakes/StatisticsMistakes.html.
11. Nick News: Stuff about me this month instead of
about Nicholas
Every newsletter, I put in a brief bit of news about my son, Nicholas. I do
it for two reasons. First, some people probably get my newsletter because they
are curious about what I'm up to in my personal life and with most families,
my personal life is wrapped up pretty tightly with my son, Nicholas. Second,
talking about Nicholas tends to humanize me a bit (I hope) for readers who are
interested in the statistics. In other words, I'm more than just a number.
In this newsletter, though, let me link to a few web pages about me
exclusively. The first is a quick summary of what I have been up to since
graduating from the University of Iowa.
*
www.pmean.com/personal/UpTo.html
I wrote this shortly after joining Facebook because a lot of my Iowa chums
were on Facebook and I had not chatted with some of them in over three
decades. I listed some of my hobbies shortly afterwards, again for the benefit
of my new Facebook friends.
*
www.pmean.com/personal/hobbies.html
Finally, someone asked a question that got me to thinking about all the
things I haven't done yet that I'd like to do.
*
www.pmean.com/10/Expectations.html
I don't want to call it my "bucket list" as I don't think I'm that close to
death's door just yet. It will be interesting to review that list in 2015 and
in 2020 to see if I still haven't gotten around to some of those things.
Think of these three links as my past, present, and future. Thanks for letting me share a bit about myself.
12. Very bad joke: A researcher is finishing up...
A researcher is finishing up a six year, ten million dollar NIH grant and
writes up in the final report "This is a new and innovative surgical procedure
and we are 95% confident that the cure rate is somewhere between 3% and 96%."
This is a joke that I wrote and that I tell in many of my classes. I have
also mentioned it several times on my old website, such as at
*
www.childrens-mercy.org/stats/weblog2006/IntervalTooWide.asp
13. Tell me what you think.
How did you like this newsletter? I have three short open ended questions at
*
https://app.icontact.com/icp/sub/survey/start?sid=6307&cid=338122You can also provide feedback by responding to this email. My three
questions are:
1. What was the most important thing that you learned in this newsletter?
2. What was the one thing that you found confusing or difficult to follow?
3. What other topics would you like to see covered in a future newsletter?
Three people provided feedback to the last newsletter. Two liked my
description of sensitivity and specificity and the other liked my explanation
about weights. One person wanted more explanation of how to use control charts.
I'm thinking of putting together a more elaborate set of webpages about quality
improvement in general and that would include several different variations of
the control chart. Suggestions for future newsletters include fixed versus
random effects models and survival analysis. For the latter topic, I would note
that my definition in the November 2009 newsletter was for the Kaplan-Meier
plot.
*
www.pmean.com/news/2009-11.html#7
There is more to survival analysis than just Kaplan-Meier, of course, so I'll
see what I can do. Let me apologize in advance though for this and earlier
suggestions that I have not found the time to write just yet. These webpages
take quite a bit of effort, especially the ones that describe some of the more
advanced perspective.
14. Upcoming statistics webinars
To sign up for any of these, send me an email with the date of the webinar
in the title line. For further information, go to
* www.pmean.com/webinars
The first three steps in selecting a sample size. Free to all!
Wednesday, April 28, 11am-noon, CDT. Abstract: One of your most critical
choices in designing a research study is selecting an appropriate sample size.
A sample size that is either too small or too large will be wasteful of
resources and will raise ethical concerns. In this class, you will learn how
to: identify the information you need to produce a power calculation; justify
an appropriate sample size for your research; and examine the sensitivity of
the sample size to changes in your research design. No statistical experience is necessary (explain).
No special hardware/software is needed (explain).
I will post a handout for this class at least 24 hours prior to the webinar.
The first three steps in a linear regression analysis with examples in
IBM SPSS. Free to all!
Wednesday, May 26, 11am-noon, CDT. Abstract: This class will give you a
general introduction in how to use SPSS software to compute linear regression
models. Linear regression models provide a good way to examine how various
factors influence a continuous outcome measure. There are three steps in a
typical linear regression analysis: fit a crude model, fit an adjusted model,
and check your assumptions These steps may not be appropriate for every linear
regression analysis, but they do serve as a general guideline. In this class
you will learn how to: interpret the slope and intercept in a linear
regression model; compute a simple linear regression model; and make
statistical adjustments for covariates. No statistical experience is necessary (explain).
No special hardware/software is needed (explain).
I will post a handout for this class at least 24 hours prior to the webinar.
What do all these numbers mean? Sensitivity, specificity, and likelihood
ratios. Free to all!
Thursday, June 10, 11am-noon, CDT.
Abstract: This one hour training class will give you a general introduction to
numeric summary measures for diagnostic testing. You will learn how to
distinguish between a diagnostic test that is useful for ruling in a diagnosis
and one that is useful for ruling out a diagnosis. You will also see an
illustration of how prevalence of disease affects the performance of a
diagnostic test. Please have a pocket calculator available during this
presentation. This class is useful for anyone who reads journal articles that
evaluate these tests. No statistical experience is necessary (explain).
No special hardware/software is needed (explain). I will post a handout for this class at least 24 hours prior to the webinar.
Here are handouts from an earlier version of this class, available in PDF
format, either
one slide per page, or
six slides per page.
15. Join me on Facebook and LinkedIn
I'm just getting started with Facebook and LinkedIn. My personal page on
Facebook is
* www.facebook.com/pmean
and there is a fan page for The Monthly Mean
*
www.facebook.com/group.php?gid=302778306676
I usually put technical stuff on the Monthly Mean fan page and personal stuff
on my page, but there's a bit of overlap.
My page on LinkedIn is
* www.linkedin.com/in/pmean
If you'd like to be a friend on Facebook or a connection on LinkedIn, I'd
love to add you.
What now?
Sign up for the Monthly Mean newsletter
Review the archive of Monthly Mean newsletters
Go to the main page of the P.Mean website
Get help
 This work is licensed under a
Creative
Commons Attribution 3.0 United States License. This page was written by
Steve Simon and was last modified on
2017-06-15. Need more
information? I have a page with general help
resources. You can also browse for pages similar to this one at
Category: Website details.
This work is licensed under a
Creative
Commons Attribution 3.0 United States License. This page was written by
Steve Simon and was last modified on
2017-06-15. Need more
information? I have a page with general help
resources. You can also browse for pages similar to this one at
Category: Website details.